[Hint]오라클 힌트란?
힌트는 SQL 튜닝의 핵심부분으로 일종의 지시구문이며 SQL에 포함되어 쓰여져 Optimizer의 실행 계획을 원하는 대로 바꿀 수 있게 해줍니다. 오라클 Optiomizer라고 해서 항상 최선의 실행 계획을 수립할 수는 없으므로 테이블 이나 인덱스의 잘못된 실행 계획을 개발자가 직접 바꿀 수 있도록 도와주는 것이 Hint 입니다.
사용자는 특정 SQL 문장에서 어떤 인덱스가 선택도가 높은지에 대해 알고 있는데 이 경우 오라클 서버의 Optimizer에 의존하여 나온 실행 계획보다 훨씬 효율적인 실행계획을 사용자가 구사할 수 있다는 것입니다.
힌트를 사용하게 되면 액세스 경로, 조인의 순서, Optiomizer의 목표(Goal)를 변경 가능하며 SQL 문장 내에 “/*+ 힌트내용 */” 형태로 사용되어 지며 여기서 주석 표시와 다른점은 더하기(+)가 있다는 것이니 주의 바랍니다.
아래의 힌트 사용예는 비용기반 옵티마이저에서 규칙-기반 옵티마이저 Mode로 바꾸기 위한 것입니다.
SQL>SELECT /*+ RULE */
ENAME, SAL
FROM EMP
WHERE EMPNO > 1000;
다음 강좌인 "힌트 사용 하는 방법"에 대해 보시면 대충 이해가 되시리라 생각 되네요...
[Hint]사용 형식
1. 힌트 구문은 기본적으로 대소문자를 구별하지 않으며 SQL 블록에서 두 가지 형태가 가능 합니다.
형식1)
/*+ hint */ ……
형식2)
--+hint ……(--+다음에 공백이 있으면 안됩니다.)
--+ 보다는 /*+ 로 시작하는 형식을 많이 사용하는데 --+ 형식의 경우 일부 버전의 DB에서는 인식이 되지 않기 때문 입니다.
2. 힌트를 포함하는 주석은 SELECT, UPDATE, DELETE, INSERT 키워드 다음에만 사용할 수 있습니다.
3. 주석에 힌트가 여러 개 있으면 각 힌트는 공백으로 구분되어야 합니다.
SQL>SELECT /*+ FULL(E) INDEX(D pk_dept) */ e.ename, d.dname
FROM EMP E, DEPT D
WHERE E.DEPTNO = D.DEPTNO
3. From절 다음에 테이블 alias를 사용한 경우에 힌트 문에 테이블 명이 와야 한다면 반드시 Alias명을 기술하도록 해야 합니다.
SQL>SELECT /*+ FULL(E) */ * FROM EMP E;
4. 힌트 구문이 잘못 사용되었더라도 SQL 문장이 올바르면 실행됩니다.
5. 구문 오류가 있는 힌트 문장을 무시하지만 같이 쓰여진 것 중에 올바른 힌트가 있다면 이는 인정을 합니다.
아래에서 FULLL이 잘못 쓰여 졌지만 INDEX(D pk_dept) 힌트는 인정됩니다.
SQL>SELECT /*+ FULLLL(E) INDEX(D pk_dept) */ e.ename, d.dname
FROM EMP E, DEPT D
WHERE E.DEPTNO = D.DEPTNO
6. 만약 힌트구문이 여러 개 쓰였는데 이들끼리 콤마(,)로 구분 되었다면 ’/*’ 부터 ‘,’ 사이의 힌트 구문까지만 유효합니다.
아래의 경우 FULL(E) 까지만 유효합니다.
SQL>SELECT /*+ FULL(E) , INDEX(D pk_dept) */ e.ename, d.dname
FROM EMP E, DEPT D
WHERE E.DEPTNO = D.DEPTNO
7. 힌트 구문간의 ‘,’가 아니라 힌트내의 인자를 취하는 구문에서 인자간의 구분을 위해 ‘,’을 사용하는 경우는 유효 합니다.
아래의 두 경우 모두 유효 합니다.
SQL>SELECT /*+ INDEX(E idx_ename) */
EMPNO, ENAME
FROM EMP E
WHERE ENAME = ‘홍길동’;
SQL>SELECT /*+ INDEX(E, idx_ename) */
EMPNO, ENAME
FROM EMP E
WHERE ENAME = ‘홍길동’;
8. 아래의 예를 참고 하세요.
SQL>SELECT /*+ FULL(SCOTT.EMP) */ * FROM EMP;(X)
SQL>SELECT /*+ FULL(EMP) */ * FROM SCOTT.EMP;(O)
SQL>SELECT /*+ FULL(E) */ * FROM SCOTT.EMP E;(O)
9. 일부 데이터베이스 개발 툴에서 힌트 구문이 먹히지 않는 경우가 있는데 이는 힌트를 주석으로 간주해 버려서 입니다.(토드 나 오렌지 등은 힌트를 정확히 인식합니다.) 이 경우 힌트가 있는 문장을 뷰로 만들어 이용하면 되는데 아래를 참고하세요.
만약 다음과 같은 힌트 문장이 인식되지 않는다면…
SQL>SELECT /*+ INDEX(E idx_ename) */ *
FROM EMP E
WHERE ENAME = ‘홍길동’;
다음처럼 뷰를 만듭니다.
SQL>CREATE OR REPLACE VIEW V_EMP AS
SELECT /*+ INDEX(E idx_ename) */ *
FROM EMP E;
뷰를 질의 합니다.
SQL>SELECT *
FROM V_EMP
WHERE ENAME = ‘홍길동’;
| 오라클 힌트(Hint) 사용 예제 | |
|
[출처] 오라클 힌트와 사용방법과 예제|작성자 정이양선
=================================================================================
=================================================================================
/*+ ALL_ROWS */
가장 좋은 단위 처리량의 목표로 문 블록을 최적화하기 위해 cost-based 접근 방법을 선택합니다. (즉, 전체적인 최소의 자원 소비)
/*+ CHOOSE */
최적자(optimizer)가 그 문에 의해 접근된 테이블을 위해 통계의 존재에 근거를 두는 SQL 문을 위해 rule-based 접근 방법과 cot-based 접근 방법 사이에 선택하게 합니다.
/*+ FIRST_ROWS */
가장 좋은 응답 시간의 목표로 문 블록을 최적화하기 위해 cost-based 접근 방법을 선택합니다. (첫번째 행을 되돌려 주는 최소의 자원 사용)
/*+ RULE */
explicitly chooses rule-based optimization for a statement block
문 블록을 위하여, rule-based 최적화를 고르는
/*+ AND_EQUAL(table index) */
그만큼 실행 계획을 선택합니다. 그리고 여럿의 single-column 색인에 그 scan을 합병하는 접근 경로를 사용합니다.
/*+ CLUSTER(table) */
선택합니다. 그리고, 클러스터는 그 명시된 테이블을 접근하기 위해 살핍니다.
/*+ FULL(table) */
그 명시된 테이블을 위하여, 전체 테이블 scan을 고르는
/*+ HASH(table) */
선택합니다. 그리고, 해쉬는 그 명시된 테이블을 접근하기 위해 운율을 살핍니다.
/*+ HASH_AJ(table) */
변환, 그 명시된 테이블을 접근하는 해쉬 antijoin으로의 NOT IN 부속 조회
/*+ HASH_SJ (table) */
변환, 그 명시된 테이블을 접근하는 해쉬 anti-join으로의 NOT IN 부속 조회
/*+ INDEX(table index) */
그 명시된 테이블을 위하여, 색인 scan을 고르는
/*+ INDEX_ASC(table index) */
그 명시된 테이블을 위하여, ascending-range 색인 scan을 고르는
/*+ INDEX_COMBINE(table index) */
어떤 색인도 INDEX_COMBINE 암시를 위해 인수로서 주어지지 않는다면, bitmap 색인의 결합이 어떤 부울의를 가장 좋은 수행 난이도 평가를 가지고 있든지 최적자는 이용합니다.
특별한 색인이 인수로서 주어진다면, 최적자는 그 특별한 bitmap 색인의 몇몇의 부울의 결합을 사용하려고 노력합니다.
/*+ INDEX_DESC(table index) */
그 명시된 테이블을 위하여, descending-range 색인 scan을 고르는
/*+ INDEX_FFS(table index) */
빠른 전체 색인 scan이 전체 테이블 scan이라기보다는 수행되게 합니다.
/*+ MERGE_AJ (table) */
변환, NOT IN 부속 조회, 그 명시된 테이블을 접근하기 위해 anti-join을 합병합니다.
/*+ MERGE_SJ (table) */
변환, 관련된 EXISTS 부속 조회, 접근으로 semi-join을 합병합니다, 그 명시된 테이블
/*+ ROWID(table) */
그 명시된 테이블을 위하여, ROWID에 의해 테이블 scan을 고르는
/*+ USE_CONCAT */
힘은 질의의 WHERE 문절에 있는 UNION ALL 집합 연산자를 사용하는 합성의 질의로 변형되는 OR 조건을 합쳤습니다.
/*+ ORDERED */
오라클이 어느 것에 순서로 테이블을 결합시키게 합니다.
/*+ STAR */
큰 있는 테이블이 최종 사용/회전율에 nested-loops를 결합시킨 힘은 그 색인에 결합합니다.
/*+ DRIVING_SITE (table) */
힘은 그것과 다른 오라클에 의해 선택된 사이트에 되는 실행을 질의합니다.
/*+ USE_HASH (table) */
오라클이 테이블이 다른 행 자원으로 해쉬 접합으로 명시되면서 각자와 합치게 합니다.
/*+ USE_MERGE (table) */
오라클이 테이블이 다른 행 자원으로 sort-merge 접합으로 명시되면서 각자와 합치게 합니다.
/*+ USE_NL (table) */
오라클이 그 명시된 테이블을 그 안의 테이블로 사용하는 nested-loops 접합과 각자와 다른 행 자원에 대한 명시된 테이블을 합치게 합니다.
/*+ APPEND */ , /*+ NOAPPEND */
데이타가 테이블로 단순히 덧붙여진다는 (or not)것 명시합니다; 무료인 현존하는 영역은 사용되지 않습니다.
단지 그 삽입 키 핵심어를 따르는 이 암시를 사용하시오.
/*+ NOPARALLEL(table) */
그 테이블이 PARALLEL 문절로 새로 만들어졌다면 테이블의 평행의 순차 검색을 무능하게 만듭니다.
/*+ PARALLEL(table, instances) */
당신이 그 연산을 위해 사용될 수 있는 동시의 슬레이브(slave) 프로세스의 요구된 수를 명시하는 것을 허락합니다.
그 세션이 가능하게 된 PARALLEL DML에 모드를 있다면, DELETE, INSERT, UPDATE 연산은 단지 parallelization에 대해 고려됩니다. (사용은 이 모드에 들어가기 위해 평행의 세션 DML을 변경합니다.)
/*+ PARALLEL_INDEX
그것은 PARALLEL 속성을 가지고 있는 색인을 분할했고 nonpartitioned했습니다.
/*+ NOPARALLEL_INDEX */
병렬이 색인을 나아가는 것을 속하게 하는 대체
/*+ CACHE */
그 블록이 찾아서 가져왔다는 것을 명시합니다. 그리고 그 테이블을 위해 그 암시에 놓여집니다. 그런데, 그것은 가장 요즈음 사용된 언제 그 버퍼 캐쉬, 가득한 테이블 scan에 있는 LRU 리스트의 끝입니다. 수행됩니다.
/*+ NOCACHE */
그 명시합니다. 그리고, 그 블록은 이 테이블을 위해 검색되면서 요즈음 사용된 언제 그 버퍼 캐쉬, 가득한 테이블 scan에 있는 LRU 리스트의 가장 작은 끝에 놓여집니다. 수행됩니다.
/*+ MERGE (table) */
오라클이 그 둘러싸는 질의 전에 복잡한 뷰나 부속 조회를 평가하게 합니다.
/*+ NO_MERGE (table) */
오라클이 mergeable 뷰를 합병하지 않게 하지 않습니다
/*+ PUSH_JOIN_PRED (table) */
개개 접합을 미는 것이 그 뷰 안으로 단정 하든 간에 비용 방식으로 최적자가 평가하게 합니다.
/*+ NO_PUSH_JOIN_PRED (table) */
접합 술부 중에서 그 뷰로 밀면서, 막는
/*+ PUSH_SUBQ */
원인은 그 실행 계획에서의 가장 이른 가능한 장소에 평가되는 부속 조회를 nonmerged했습니다.
/*+ STAR_TRANSFORMATION */
최적자가 그 변형이 사용된 가장 좋은 계획을 사용하는 제작
* DEGREE의 의미 및 결정
Parallel Query에서 degree란 하나의 operation 수행에 대한 server process의 개수 입니다.
이러한 degree 결정에 영향을 주는 요인들에는 다음과 같은 것들이 있습니다.
(1) system의 CPU 갯수
(2) system의 maximum process 갯수
(3) table이 striping되어 있는 경우, 그 table이 걸쳐있는 disk의 갯수
(4) data의 위치 (즉, memory에 cache되어 있는지, disk에 있는지)
(5) query의 형태 (예를 들어 sorts 혹은 full table scan)
한 사용자만이 parallel query를 사용하는 경우, sorting이 많이 필요한 작업과 같은 CPU-bound 작업의 경우는 CPU 갯수의 1 ~ 2배의 degree가 적당하며, sorting보다는 table scan과 같은 I/O bound 작업의 경우는 disk drive 갯수의 1 ~ 2배가 적당합니다.
동시에 수행되는 parallel query가 많은 경우에는 위의 각 사용자의 degree를 줄이거나 동시에 사용하는 사용자 수를 줄여야 합니다.
=================================================================================
=================================================================================
SQL*Plus로 scott 계정으로 로그인한 후 emp 라는 테이블을 만들어 실습을 합니다.
SQL> create table test (
2 id number not null primary key,
3 name varchar2(20)
4 );
테이블이 생성되었습니다.
데이터는 5건 넣는데 순서를 잘 보시기를 바랍니다.
기본적으로 select하면 넣은 순서대로 나옵니다.
SQL> insert into test values (4,'4길동');
1 개의 행이 만들어졌습니다.
SQL> insert into test values (3,'3길동');
1 개의 행이 만들어졌습니다.
SQL> insert into test values (5,'5길동');
1 개의 행이 만들어졌습니다.
SQL> insert into test values (1,'1길동');
1 개의 행이 만들어졌습니다.
SQL> insert into test values (2,'2길동');
1 개의 행이 만들어졌습니다.
SQL> select * from test;
ID NAME
---------- --------------------
4 4길동
3 3길동
5 5길동
1 1길동
2 2길동
그래서 이름으로 정렬하여 볼려면...
(그런데 order by는 사용하지 말라고 권고 하고 있죠.. .별도의 소트를 위한 공간을 이용하여 데이터를 정렬하므로 대량의 데이터일땐 DB에겐 OverHead 가 있는거죠... .)
SQL> select * from test order by name;
ID NAME
---------- --------------------
1 1길동
2 2길동
3 3길동
4 4길동
5 5길동
이 경우 인덱스를 이용하면 쉽게 정렬된 데이터를 볼 수가 있습니다.
(멋지죠^^)
SQL> create index idx_test_name on test(name);
인덱스가 생성되었습니다.
SQL>select /*+index(TEST,IDX_TEST_NAME)*/ name from test
where name is not null;
ID NAME
---------- --------------------
1 1길동
2 2길동
3 3길동
5 3길동
4 4길동
그럼 이번에는 이름 역순으로 데이터를 가지고 올려고 합니다.
어떻게 할까요.. 아래처럼 order by를 descending으로 할까요...?
SQL> select * from test order by name desc;
ID NAME
---------- --------------------
4 4길동
3 3길동
5 3길동
2 2길동
1 1길동
이럴때 힌트라는 것을 이용하면 쉽게 해결할 수가 있습니다...
SQL> select /*+ index_desc (test, idx_tes_name) */ *
2 from test
3 where name is not null;
ID NAME
---------- --------------------
1 1길동
2 2길동
3 3길동
5 3길동
4 4길동
=================================================================================
=================================================================================
출처 : DB사랑넷
| 힌트에 대해서...질문있습니다. | |||||
|
작성자 |
김선경(somcandy) |
작성일 |
2007-05-04 11:22:19ⓒ 2007-05-04 11:22:38ⓜ |
조회수 |
1,620 |
|---|---|---|---|---|---|
|
초보자 질문입니다. |
1 번이 바른 사용예로 알고 있습니다.
단 힌트는 장기의 훈수와 같아서
옵티마이저가 반드시 힌트를 받아 들이지는 않습니다.
또한 문법에 틀린 힌트는 무시 하고요.
ㅅㄱ
1번이 맞는것 같은데요. hint를 잘 못 사용하면 옵티마이져가 무시하는걸로 알고 있습니다.
이 사이트 상당히 많은 사람이 접속하는군요.
제가 답글 담과 동시에 동일한 답을 누가 달았었네요. ㅎㅎ
hint는 복수로 사용할 수 있습니다.
단, 복수를 사용하기 위해서는 상반된 내용을 기재하면 안되며
hint syntax가 틀렸다면, oracle optimizer가 hint를 처리하지 않습니다.
또한, 선행hint와 후행hint가 있다면, 선행 hint에 의해서
결정되는 후행 hint가 있습니다.
그런것도 염두해 두셔야만 할 것입니다.
예를들면,
/*+ ordered use_nl(테이블1, 테이블2) index_desc(테이블1 테이블1의 인덱스명) index(테이블2 테이블2의 인덱스명)*/
과 같은 것이지요..
일단, hint의 access path에 대해서 알아 보시고,
join에 대한 hint를 확인하셔야만 할 것입니다.
님이 쓰셨던 예제중
select /*+ index_desc(table_name table_index) FULL(table_name) */
from table_name
는 hint 문법상 틀리지 않았지만
oracle optimizer가 보기엔 "①index를 사용하라 ②인덱스를 사용하지 마라"
라고 하는 2가지 명령어가 들어 있습니다.
따라서, where절이나 join 형태에 따라서 어떤 hint(index,full)를 사용할지 결정하거나
모두를 패기시킬 것입니다.
이 댓글은 2007-05-05 21:07:33에 마지막으로 수정되었습니다.
네..감사합니다.
저는 단지 두개힌트를 같이 사용해도 되는지 궁금했습니다.
그리고 순서와 상관없는거죠?
그니까 꼭 먼저 썻다고 먼저꺼 힌트 먼저 실행하고고 나중꺼 실행하고 이런식인지요?
아니면 오티마이저 마음대로인지???
그것도 갑자기 궁금해져서요...
대답해주시면 감사하겠습니다. 혹여나 보실 수 있으면 ...제 질문을...
옵티마이저가 보고 수행 할 겁니다.
여러개의 인덱스 중에 제일 최적화 인덱스라 판단하는 것을 타듯이....
(밥사주세요 꾸벅 ㅋㅋ)
=================================================================================
=================================================================================
CREATE TABLE t01(
id VARCHAR2(20),
num VARCHAR2(20),
r_date VARCHAR2(8) NOT NULL
)
CREATE TABLE t02(
c01 VARCHAR2(20) NOT NULL,
c02 VARCHAR2(20) NOT NULL,
c03 VARCHAR2(20) NOT NULL,
id VARCHAR2(20),
num VARCHAR2(20),
p_date VARCHAR2(8),
PRIMARY KEY (c01, c02, c03)
)
//위의 두개의 테이블이 있습니다
insert into t01 (id,num,r_date) VALUES ('aaa','1111','20010101');
insert into t01 (id,num,r_date) VALUES ('bbb','1112','20010102');
insert into t01 (id,num,r_date) VALUES ('ccc','1113','20010103');
insert into t01 (id,num,r_date) VALUES ('ddd','1114','20010104');
insert into t01 (id,num,r_date) VALUES ('eee','1115','20010105');
insert into t02 (c01,c02,c03,id,num,p_date) VALUES ('ee1','ww1','qq1','aaa','1111','20010101');
insert into t02 (c01,c02,c03,id,num,p_date) VALUES ('ee2','ww2','qq2','bbb','1112','20010102');
insert into t02 (c01,c02,c03,id,num,p_date) VALUES ('ee3','ww3','qq3','ccc','1113','20010103');
insert into t02 (c01,c02,c03,id,num,p_date) VALUES ('ee1','ww4','qq4','ddd','1114','20010104');
insert into t02 (c01,c02,c03,id,num,p_date) VALUES ('ee2','ww5','qq5','eee','1115','20010105');
//위의 데이터를 입력 했구요
CREATE INDEX idx_t01 on t01(r_date desc)
//t01 테이블에 인덱스 힌트를 주기위해 인덱스 생성을 했습니다
//(오라클 8.0 이라서 내부쿼리에서 order by가 안되는 관계로..)
Select /*+ index_desc(t01 idx_t01) */ * from t01
//조인을 하지 않고 위와 같이 쿼리를 사용하면 r_date desc 재대로 나옵니다.
Select /*+ index_desc(t01 idx_t01) */ A.id, A.num, A.r_date, B.p_date From t01 A, t02 B where A.id = B.id and A.num = B.num
//위와 같이 쿼리를 하면 r_date desc 로 정렬이 안됩니다.
//t02의 PRIMARY KEY 때문일거 같아서 PRIMARY KEY 삭제해고 해보았지만r_date desc 로 정렬이 안됩니다.
//조인 후에 인덱스 힌트가 잘못되어 있는건지막막 하기만 하네요.
//많은 조언 부탁 드리겠습니다.
질문자인사 Select /*+ index_desc(t01 idx_t01) */ t01.id, t01.num, t01.r_date as r_date, t02.p_date From t01, t02 where t01.id = t02.id and t01.num = t02.num and t01.r_date > ' '; 감사 합니다. 위의 쿼리로 수
제시하신 조인 문장은 현재 Hash Join으로 처리되고 있습니다. ^^
원하시는 처리는 조인 문장이 Nested Loops로 처리되어야하만 가능한 것입니다.
이를 위해서 다음 두가지 조정을 하시면 됩니다.
1.세션 환경 조절 : hash_join_enabled를 false로...
2.인덱스가 사용될 수 있도록 dummy 조건 추가 : A.r_date > ' '
주의할 사항
1.인덱스를 desc로 생성해 두었기 때문에 힌트는 그냥 index로 사용해야 합니다.
만약 인덱스를 그냥 생성했다면 힌트는 index_desc를 사용해야 합니다.
2.문장에서 테이블 Alias를 사용했다면 힌트 구문에서도 Alias를 사용해야 합니다.
SQL> alter session set hash_join_enabled=false;
SQL> Select /*+ index(A idx_t01) */
A.id, A.num, A.r_date, B.p_date
From t01 A, t02 B
where A.id = B.id
and A.num = B.num
and A.r_date > ' ';
행운이 있기를... ^^
=================================================================================
=================================================================================
*오라클 힌트 사용예
--------------------------------------------------
select /*+ index( idx_col_1 ) */
name, age, hobby
from member
--------------------------------------------------
*오라클 힌트 사용표
| INDEX ACCESS OPERATION 관련 HINT | ||
| HINT | 내용 | 사용법 |
| INDEX | INDEX를 순차적으로 스캔 | INDEX(TABLE명, INDEX명) |
| INDEX_DESC | INDEX를 역순으로 스캔 | INDEX_DESC(TABLE명, INDEX명) |
| INDEX_FFS | INDEX FAST FULL SCAN | INDEX_FFS(TABLE명, INDEX명) |
| PARALLEL_INDEX | INDEX PARALLEL SCAN | PARALLEL_INDEX(TABLE명,INDEX명) |
| NOPARALLEL_INDEX | INDEX PARALLEL SCAN 제한 | NOPARALLEL_INDEX(TABLE명,INDEX명) |
| AND_EQUALS | INDEX MERGE 수행 | AND_EQUALS(INDEX_NAME, INDEX_NAME) |
| FULL | FULL SCAN | FULL(TALBE명) |
| JOIN ACCESS OPERATION 관련 HINT | ||
| HINT | 내용 | 사용법 |
| USE_NL | NESTED LOOP JOIN | USE_NL(TABLE1, TABLE2) |
| USE_MERGE | SORT MERGE JOIN | USE_MERGE(TABBLE1, TABLE2) |
| USE_HASH | HASH JOIN | USE_HASH(TABLE1, TABLE2) |
| HASH_AJ | HASH ANTIJOIN | HASH_AJ(TABLE1, TABLE2) |
| HASH_SJ | HASH SEMIJOIN | HASH_SJ(TABLE1, TABLE2) |
| NL_AJ | NESTED LOOP ANTI JOIN | NL_AJ(TABLE1, TABLE2) |
| NL_SJ | NESTED LOOP SEMIJOIN | NL_SJ(TABLE1, TABLE2) |
| MERGE_AJ | SORT MERGE ANTIJOIN | MERGE_AJ(TABLE1, TABLE2) |
| MERGE_SJ | SORT MERGE SEMIJOIN | MERGE_SJ(TABLE1, TABLE2) |
| JOIN시 DRIVING 순서 결정 HINT | ||
| HINT | 내용 | |
| ORDERED | FROM 절의 앞에서부터 DRIVING | |
| DRIVING | 해당 테이블을 먼저 DRIVING- driving(table) | |
| 기타 힌트 | ||
| HINT | 내용 | |
| append | insert 시 direct loading | |
| parallel | select, insert 시 여러 개의 프로세스로 수행- parallel(table, 개수) | |
| cache | 데이터를 메모리에 caching | |
| nocache | 데이터를 메모리에 caching하지 않음 | |
| push_subq | subquery를 먼저 수행 | |
| rewrite | query rewrite 수행 | |
| norewrite | query rewrite 를 수행 못함 | |
| use_concat | in절을 concatenation access operation으로 수행 | |
| use_expand | in절을 concatenation access operation으로 수행 못하게 함 | |
| merge | view merging 수행 | |
| no_merge | view merging 수행 못하게 함 | |
[출처]
=================================================================================
=================================================================================
참조 : http://blog.naver.com/wideeyed?Redirect=Log&logNo=80036376623
참조 : http://piyoro.tistory.com/39
참조 : http://download.oracle.com/docs/cd/B19306_01/server.102/b14200/sql_elements006.htm#SQLRF00219
오라클 힌트란 ?
⑴ 개요
힌트는 SQL 튜닝의 핵심부분으로 일종의 지시구문이다
SQL에 포함되어 쓰여져 Optimizer의 실행 계획을 원하는 대로 바꿀 수 있게 해준다. 오라클 Optimizer라고 해서 항상의
최선의 실행 계획을 수립할 수는 없으므로 테이블 이나 인덱스의 잘못된 실행 계획을 개발자가 직접 바꿀 수 있도록 도와주는
것이다. 사용자는 특정 SQL 문장에서 어떤 인덱스가 선택도가 높은지에 대해 알고 있는데 이 경우 오라클 서버의
Optimizer에 의존하여 나온 실행 계획보다 훨신 효율적인 실행계획을 사용자가 구사할 수 있다.
⑵ 사용법
힌트를 사용하여 아래와 같은 것들을 할 수 있다.
액세스 경로, 조인순서, 병렬 및 직렬처리 ,Optimizer의 목표(Goal)를 변경 가능
⑶ 형태
SQL 문장 내에 [/*+ 힌트 내용 */] 이 추가된다.
주의! 주석 표시에 더하기(+)가 있다.
⑷ 예제
ex.)
Insert /*+ append*/ into text00...
insert /*+parallel*/ into test00...
⑸ 오라클 힌트 사용표
① index access operation 관련 hint

② join access operation 관련 hint
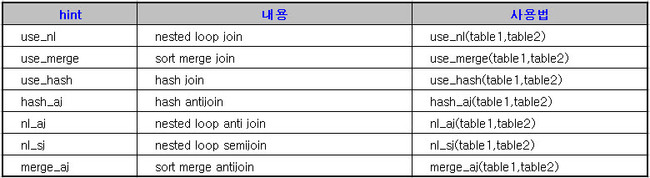
③ JOIN 시 Driving 순서 결정 hint

④ 기타 힌트

[출처] 오라클 Hint 정리 ... (tonkjsp) |작성자 tonk000
=================================================================================
